图文识别训练与跨模态预训练 人工智能基础软件开发新篇章
随着人工智能技术的快速发展,图文识别训练与机器推理已成为推动行业进步的重要驱动力。在机器推理系列第五弹中,文本与视觉的融合成为焦点,跨模态预训练技术正展现出前所未有的潜力,为人工智能基础软件开发带来新的机遇与挑战。
一、图文识别训练:从单模态到多模态的演进
传统的图文识别训练主要关注单一模态的数据处理,例如文本识别或图像识别。实际应用中,信息往往以多模态形式存在,如社交媒体中的图片配文、视频中的语音和字幕等。因此,研究人员开始探索跨模态训练方法,通过融合文本与视觉数据,提升模型的综合理解能力。例如,基于深度学习的模型能够同时分析图像中的物体和文本描述,实现更精准的场景识别与内容生成。
二、机器推理系列第五弹:文本与视觉的深度融合
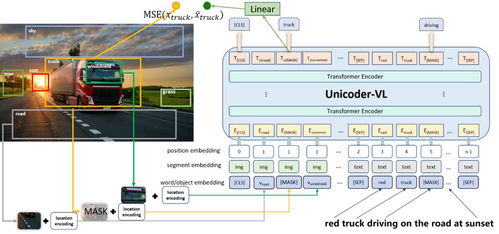
在机器推理系列的最新进展中,文本与视觉的跨模态预训练成为关键突破点。通过大规模多模态数据集(如图文对、视频文本对)的训练,模型能够学习文本与视觉之间的语义关联,从而在推理任务中表现出色。例如,在视觉问答(VQA)任务中,模型不仅需要识别图像中的内容,还需理解问题文本的意图,给出准确的答案。跨模态预训练技术通过自监督学习,让模型在无标签数据中自动发现模态间的内在联系,大大提升了泛化能力。
三、跨模态预训练新进展:技术突破与应用前景
跨模态预训练技术取得了显著进展。一方面,模型架构不断优化,如Transformer-based模型(如ViT、BERT)的扩展,使得文本与视觉特征的融合更加高效。另一方面,预训练策略的创新,如对比学习、掩码建模等,增强了模型对多模态数据的理解能力。这些进展不仅推动了学术研究,还为实际应用奠定了基础,例如智能客服中的图文交互、自动驾驶中的环境感知等。
四、人工智能基础软件开发的机遇与挑战
跨模态预训练技术的兴起,为人工智能基础软件开发带来了新机遇。开发者可以利用开源预训练模型(如OpenAI的CLIP、谷歌的ViLBERT)快速构建多模态应用,降低开发门槛。软件工具链的完善,如PyTorch、TensorFlow对多模态训练的支持,进一步加速了创新进程。挑战也随之而来:数据隐私与安全、模型可解释性、计算资源需求等问题仍需深入解决。随着技术的成熟,人工智能基础软件将更注重易用性、可扩展性和伦理合规性。
图文识别训练与跨模态预训练正在重塑人工智能领域。通过文本与视觉的深度融合,机器推理能力不断提升,为人工智能基础软件开发注入了新活力。随着技术的不断突破,我们有望看到更加智能、高效的多模态应用,推动社会迈向更智慧的时代。
如若转载,请注明出处:http://www.hongxinxinxikeji.com/product/62.html
更新时间:2026-05-28 03:43:00